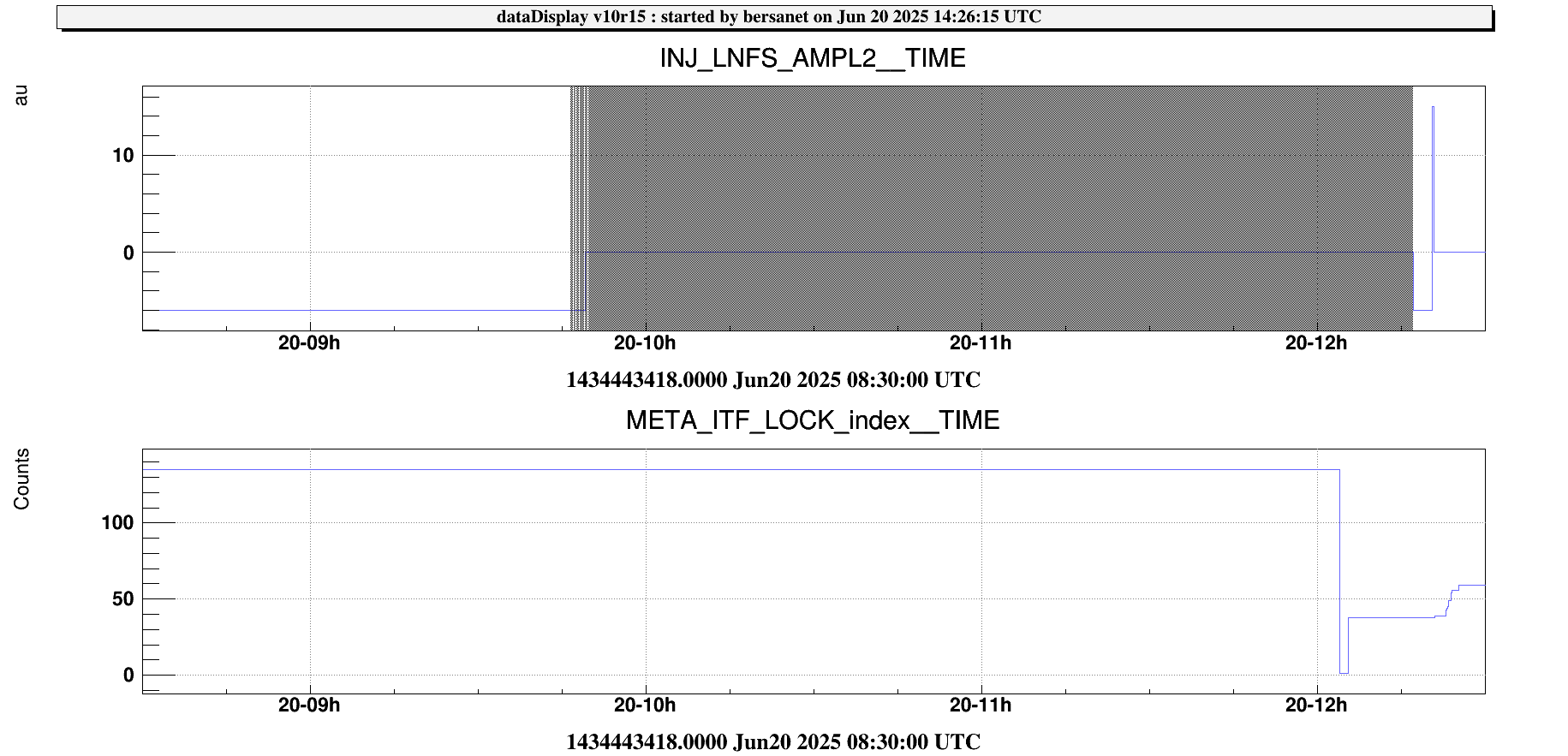
Later today the issue happened again. The FbsISC framebuilder lost connection with the Lnfs100 process:
FbsISC:2025-06-20-09h49m05-UTC>ERROR..-FbsCmSmsData> GPS:1434448163 No data extracted for Lnfs100
2025-06-20-10h54m40-UTC>WARNING-Main> local - gps 1434452098-130968000, prev 1434452097-002215000(000000000) - frDt 1, dt 1.13097 - nb 1 - tmo 0.004522
Lnfs100:
2025-06-20-07h46m00-UTC>INFO...-Sent AMPL 2 -6 1 command to LNFS1
2025-06-20-09h49m04-UTC>INFO...-CfgReachState> Error(Error) Ok
2025-06-20-09h49m04-UTC>WARNING-Timeout from worker process!
2025-06-20-09h50m09-UTC>WARNING-Timeout from worker process!
However the problem became evident only later, once we actually tried to access the LNFS data, i.e. during FmodErr at the beginning of the lock acquisition (Figure 1).
This time the Lnfs100 was apparently dead from the VPM, but connecting to olserver129 I could see both processes actually still alive:
virgorun@olserver129[~]: ps aux | grep Lnfs100
virgorun 32242 0.0 0.0 113424 1692 ? S 04:24 0:00 bash /virgoApp/PyLnfs100/v4r1p1/Linux-x86_64-CL7/bin/PyLnfs100-conda /virgoData/VirgoOnline/Lnfs100.cfg Lnfs100
virgorun 32714 1.5 0.9 741672 75620 ? SNl 04:24 9:11 python3 /virgoApp/PyLnfs100/v4r1p1/scripts/PyLnfs100.py /virgoData/VirgoOnline/Lnfs100.cfg Lnfs100
virgorun 33491 0.0 0.0 112824 992 pts/8 R+ 14:15 0:00 grep --color=auto Lnfs100
virgorun@olserver129[~]: kill -9 32242 32714
virgorun@olserver129[~]: ps aux | grep Lnfs100
virgorun 33582 0.0 0.0 112820 988 pts/8 S+ 14:16 0:00 grep --color=auto Lnfs100
After killing the processes (as virgorun) I could restart it from VPM, then the same steps done by Alain (remove SMS from Lnfs100 and ReloadConfig, both actions on FbsISC) restored the proper communication.
In case this happens again the same procedure can be followed; however, most probably it won't be sufficient: the issue happens when the INJ_MAIN node resets the modulation amplitude in the Lnfs and cannot read it back. But the command is not actually received because the communication was lost already before.
So, if INJ_MAIN still notifies "Waiting for 8MHz mod ampl going to default", one should send again the command from a standard iPython shell:
cm_send('Lnfs100','SET8AMPL',15)

{kind=link}