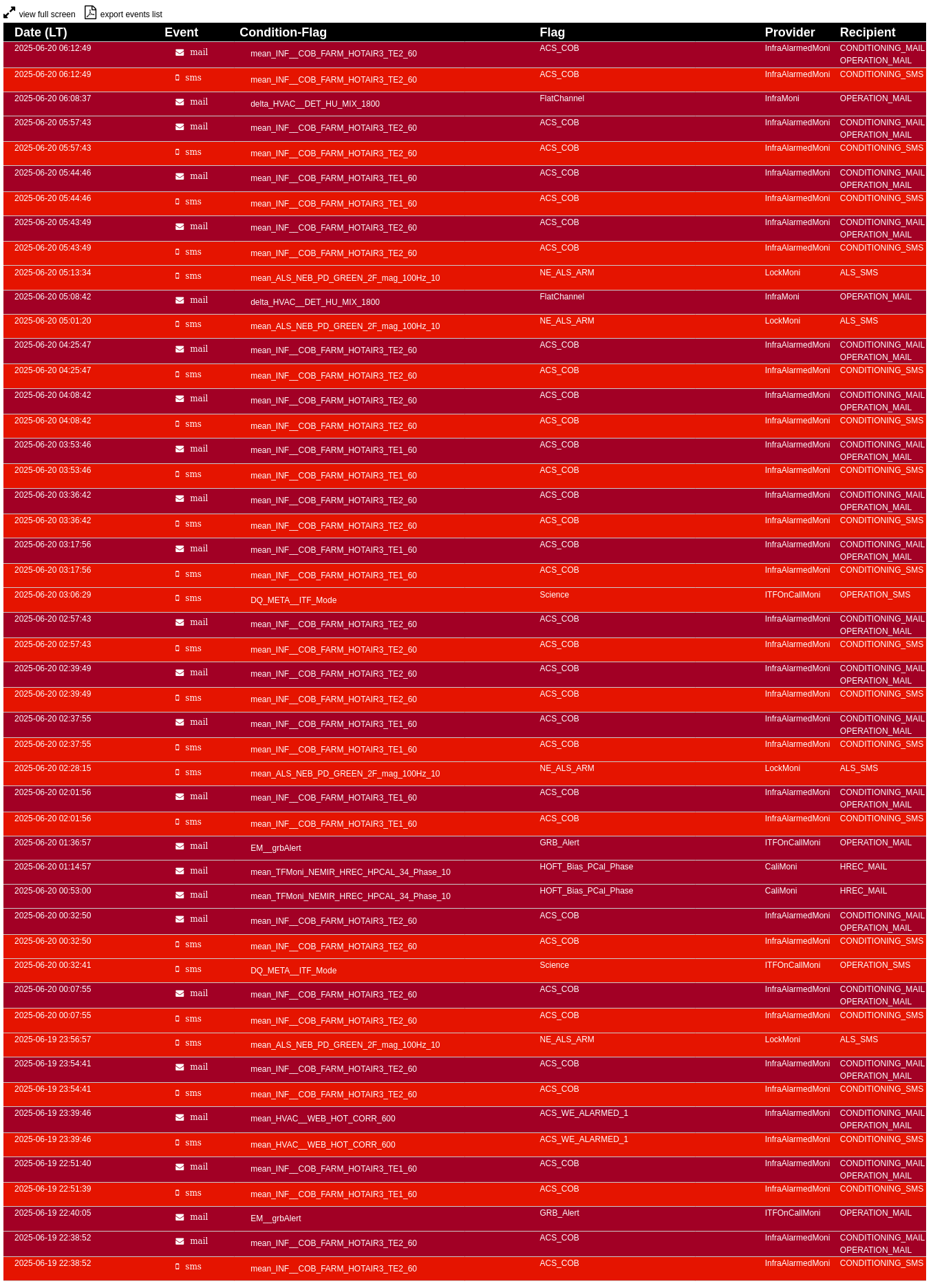
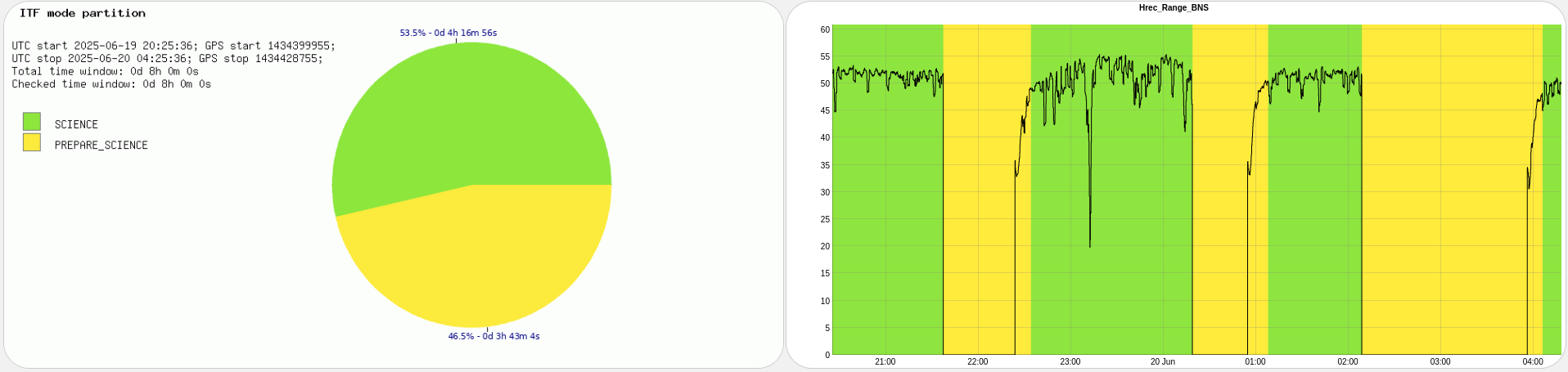
ITF found locked at LOW_NOISE_3 in SCIENCE mode.
At 21:37 UTC ITF unlocked due to Instability in the LN2 NI_MAR -> NE_MIR reallocation filter or end TM (MIR or MAR) correction saturation. Unfortuntely the unlock caused an opening of WI ID loop. Properly closed.
Relocked at first attempt. SCIENCE mode set at 22:35 UTC.
At 00:19 UTC ITF unlocked again due to ASC DIFFp TY diverging or end TM (MIR or MAR) correction saturation.
Autorelocked at first attempt. SCIENCE mode at 01:08 UTC.
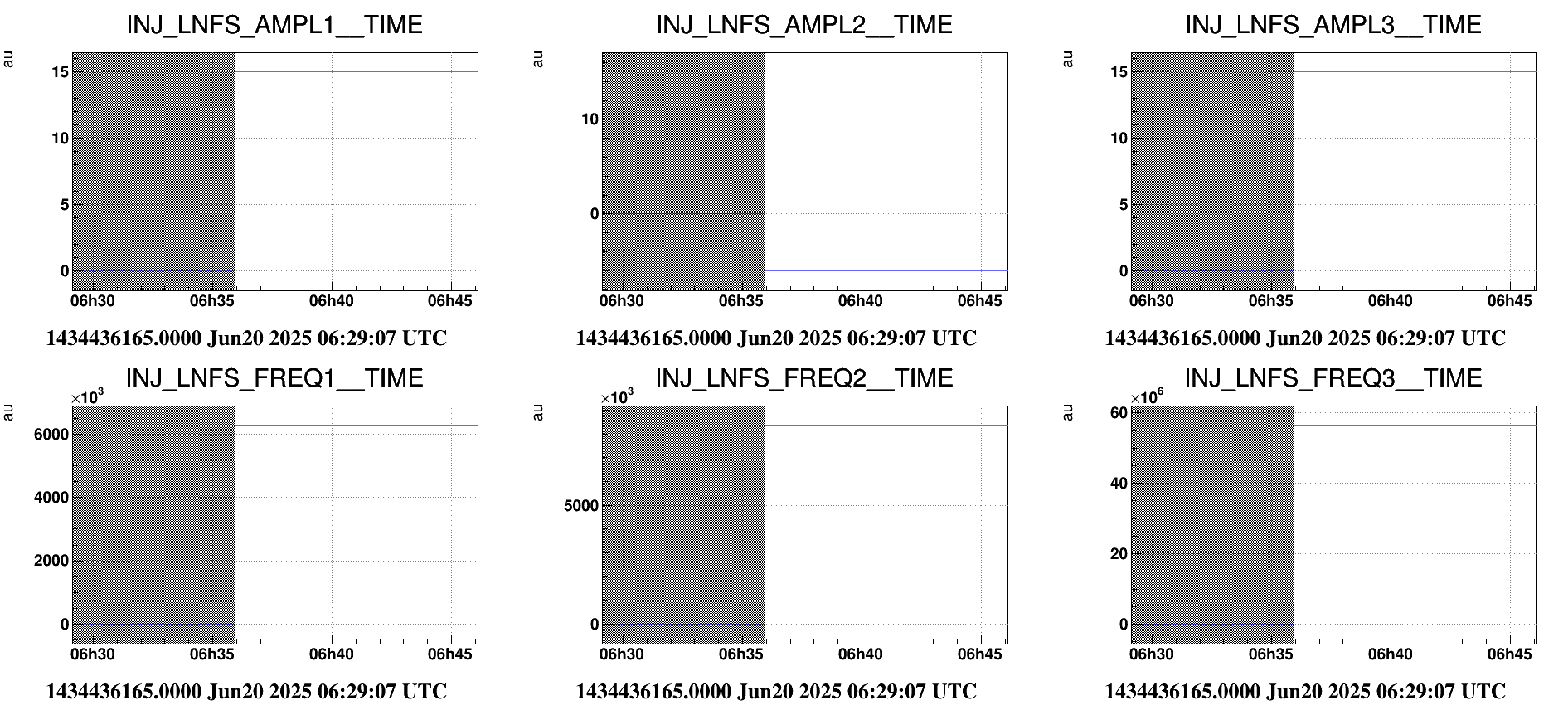
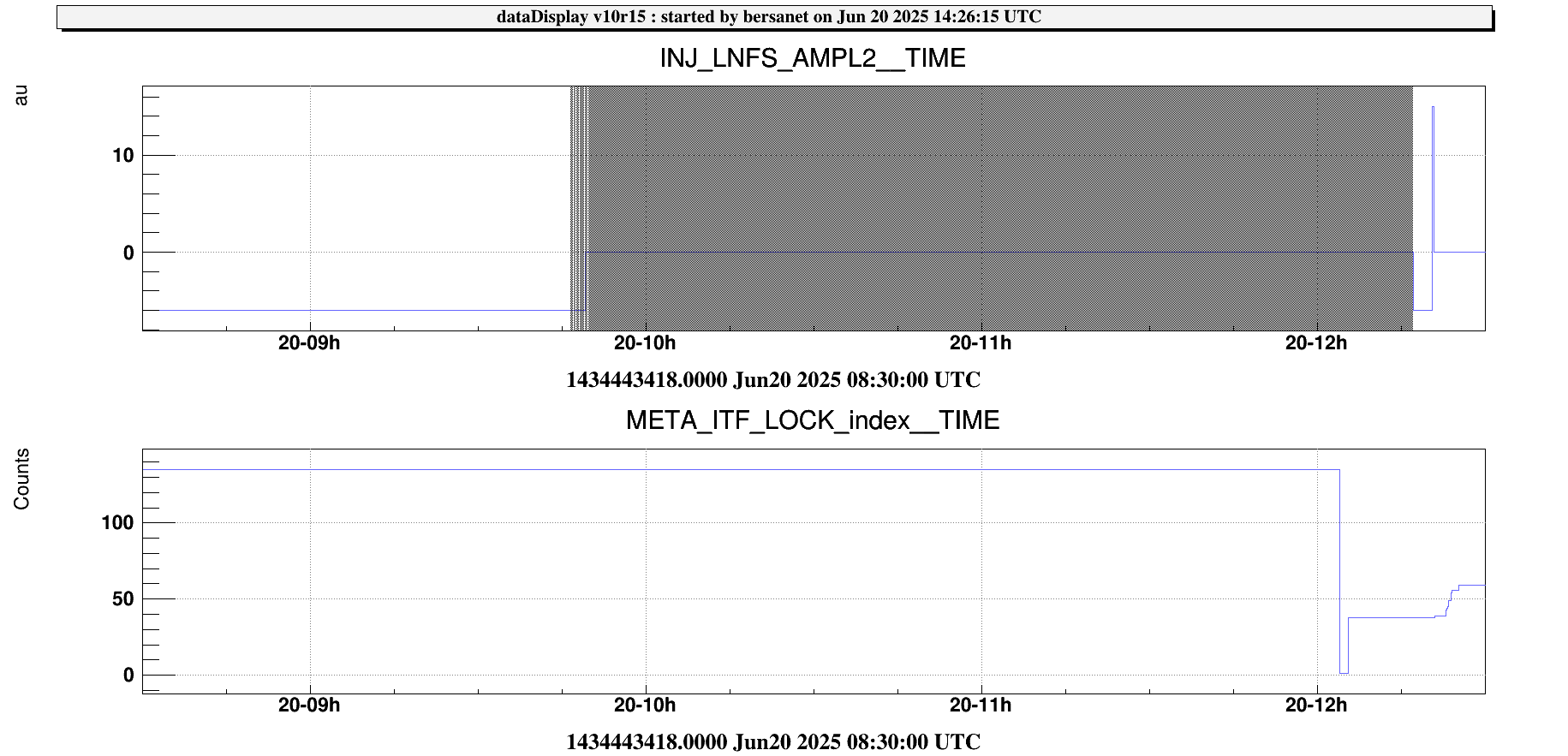
ITF unlocked again at 02:09 UTC (TBC). Unfortunately INJ_MAIN was not able to complete FmodErr. The node was stuck looping between IMC_RESTORED and FMODERR_TUNED due to a problem with LNFS.
Under suggestion of ISC expert I temporary bypassed FmodErr via ITF_LOCK.ini "fmoderr_skip = True".
Relocked after two cross-alignments in ACQUIRE_DRMI. SCIENCE mode at 04:07 UTC.
Guard Tour (UTC)
20:56 - 21:35
23:03 - 23:41
01:06 - 01:46
03:08 - 03:50
DAQ
01:27 UTC - Lnfs100 crashed. Killed via shell, restarted via VPM.
DAQ
(20-06-2025 03:00 - ) LNFS not responding. INJ_MAIN metatron node stuck before FMODERR_TUNED.
ISC
(20-06-2025 03:00 - 20-06-2025 03:10) Operator on site with expert from remote
Status: Ended
Description: FmodErr
Actions undertaken: INJ_MAIN Metatron node stuck while trying to reach FMODERR_TUNED due to a problem with LNFS.
FmodErr disabled via "fmoderr_skip = True" in ITF_LOCK.ini.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}