This morning I received an alarm about TCS Chillers. Checking on the DMS and VPM I could see a flooding of red flags and I came onsite to check the situation.
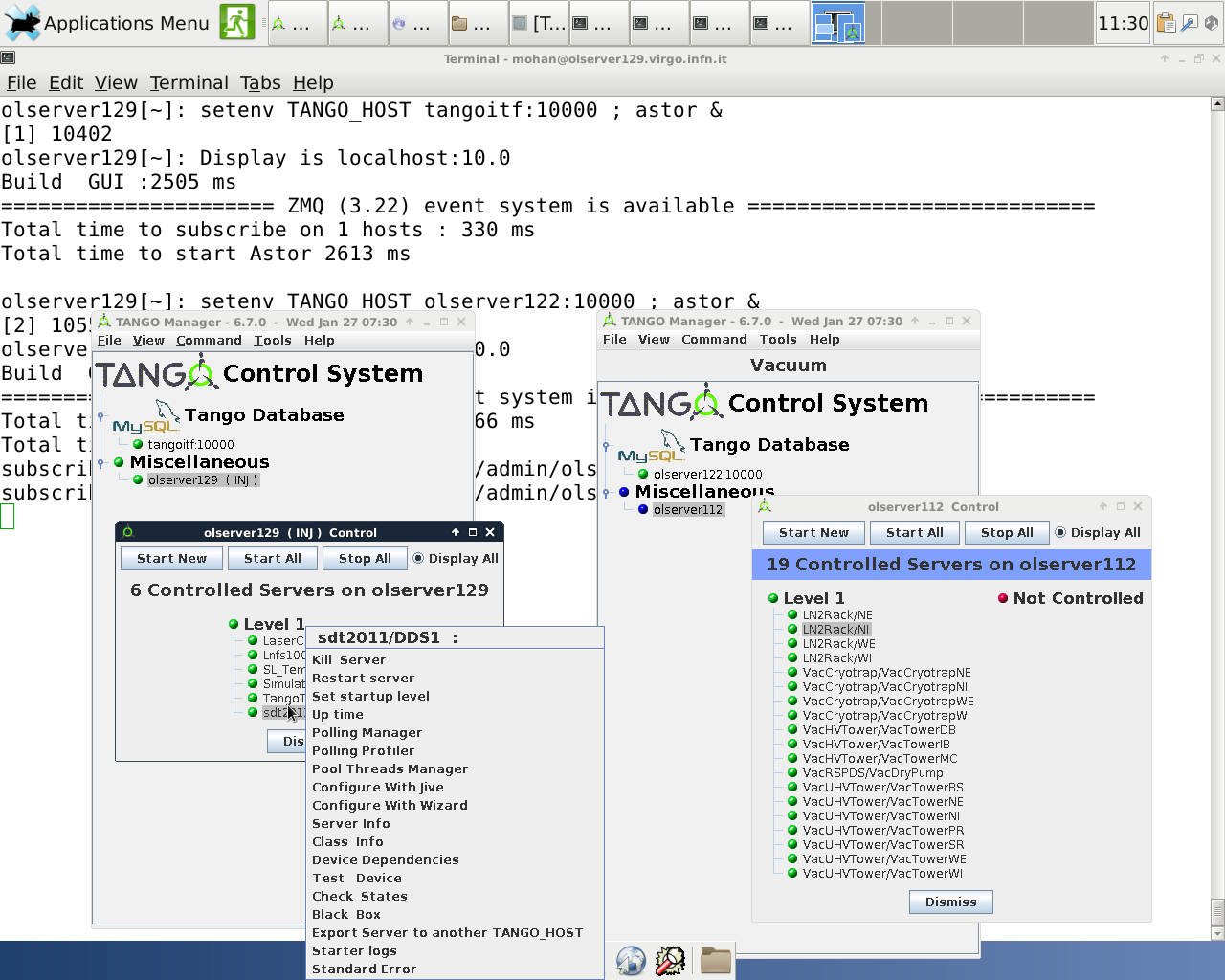
Once onsite it was clear that the problem was at network level with some of the devices on the Central, NE and WE Buildings not reachable. I could not spot any evident electrical problem as a cause of the network outage.
After consulting with Antonella over the phone, Stefano came onsite and started fixing the problem (see his entry for details). The recovery also implied the reboot of the rtpc servers.
Situation could be almost fully recovered by resetting all devices disconnected from network (such as netcom bridges) and by restarting all processes running on rtpc and the whole DAQ with Loic support.
The communication with Cryo and Tower vacuum devices needed also to be restored (all corresponding Tango DAQ brides are back providing data).
The remaining problems are associated to missing SAT DSP g-names which are blocking the automation. The situation could not be recovered by stopping/restarting all SAT tango processes.
Since I could not find Valerio over the phone I leave the current situation and recovery will be continued tomorrow morning.
{kind=link}