Tonight, at the end of the afternoon shift, it was intended to launch a YAG Absorption Measurement. In the end we managed to, but with some bumps along the way. As reported in #59271 and #59274, after locking in CARM_NULL_1F we setup the automation in order to perform the measurement on the DET HWS (NI mirror).
During the first step of the process, i.e. the timeout where the lock is kept before doing anything, I noticed the PyHWS process (the one which launches the hwsAna.py acquisition script, see #58035, #57352 and others) having a way too low Process Uptime, about a few hours. I then noticed that today it crashed and it was restarted from VPM. Unfortunately this is not what we want for PyHWS, but being the process in a very peculiar (hopefully temporary) state, there is no fault in that.
The thing is that, as explained in #59016, currently we use PyHWS launched manually from a human userspace (formerly fcarbogn), in order to possibly avoid the unexpected interruption of the HWS acquisition.
So I tried to relaunch it from my shell manually (bersanet@servertcs1, ssh-ed from ctrl23), using the same command and configuration file as the VPM instance, with Metatron and its timers in ABSORPTION_MEAS_INIT already running.
Unfortunately, the process launched but no cm commands launched to acquire with the HWS were successful; so both TCS_MAIN and ITF_LOCK were paused while the issue was investigated.
I started to see (thanks to the recent introduction of a logfile) that the hwsAna.py process (the one living in /virgoDev/TCS_HWS/Python/HWS_ANA/v3r0/) was crashing due to Python errors about indentation. I could not write either the file or the directory where it lives into, so I duplicated the file into hwsAna_DB.py and edited as user optics. PyHWS was updated in VPM to use this new script. After fixing the indentation errors, I had errors about print statements written as in Python2, with my shell being Python3.
Long story short, now PyHWS runs from user bersanet, on a Python2 shell in servertcs1, spawned from ctrl23 via ssh.
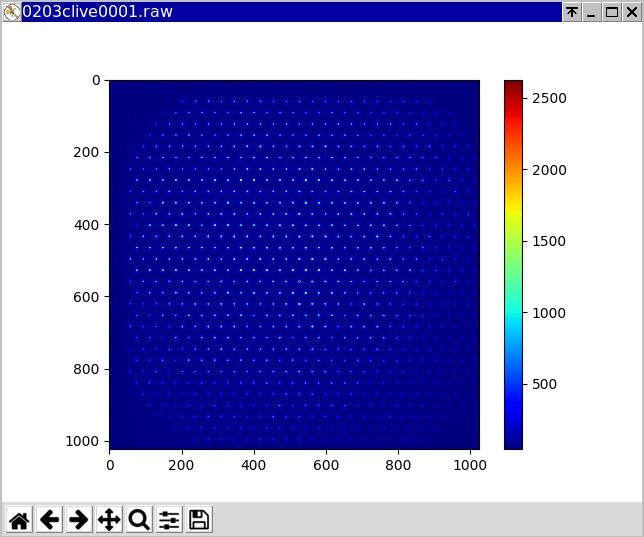
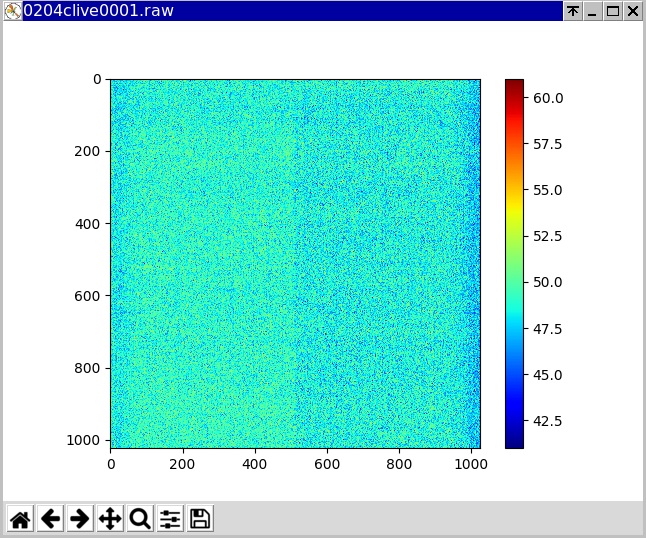
The acquisition of the ref images was tested, which went fine, then the live ones (coherent with the wanted measurement), with no issues.
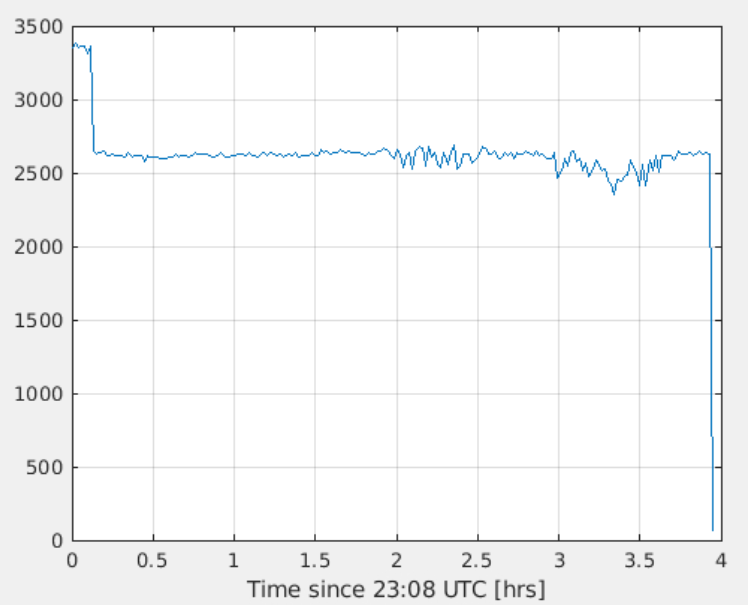
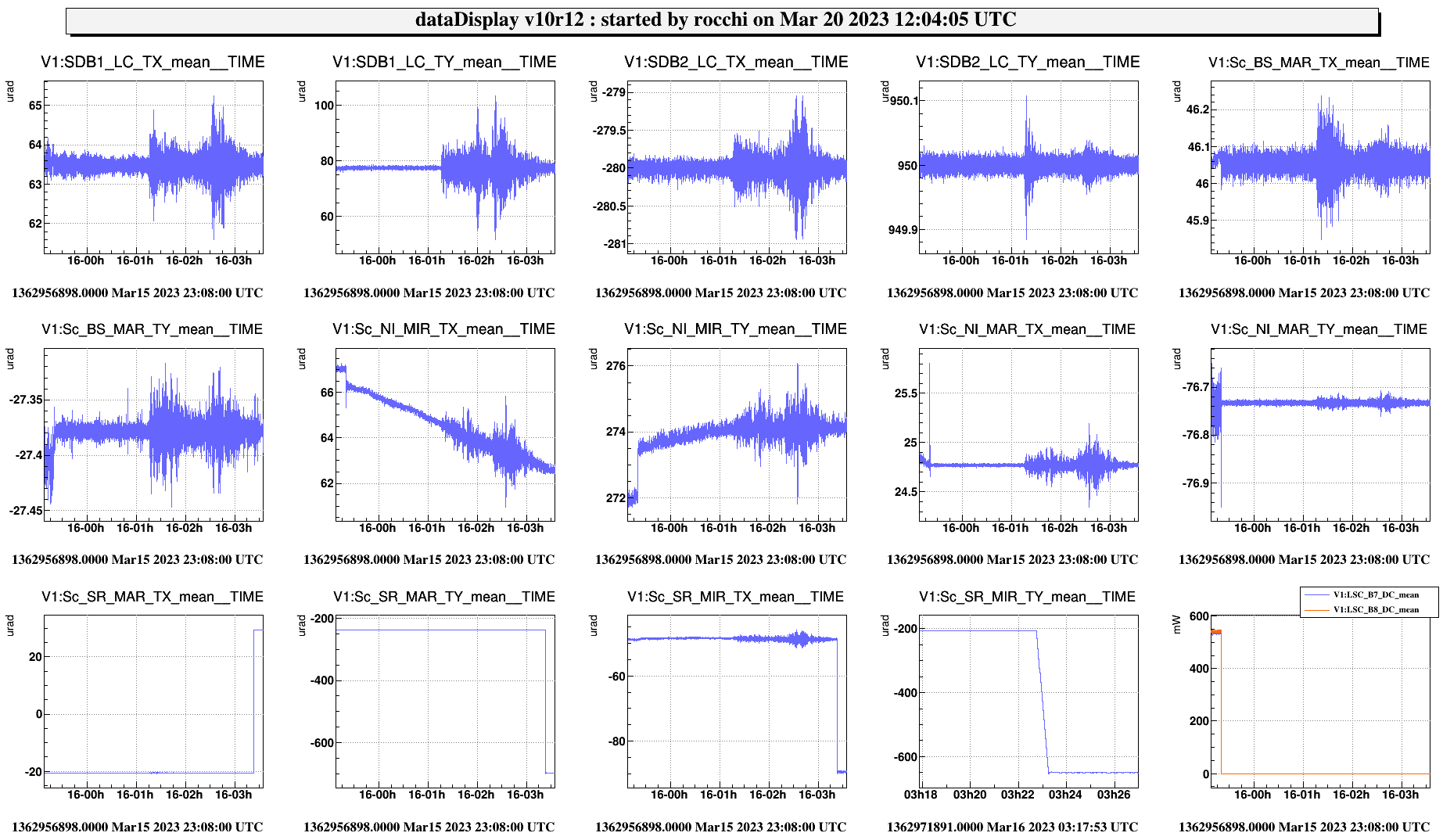
After 6 wavefronts I un-paused both ITF_LOCK and TCS_MAIN, but the timer (HWS acquisition with ITF locked) had expired (I guess as the node itself, so its timers, is still running and only the execution of the run() method is actually paused). So the automation moved already to unlocking the ITF and proceed with the cold measurement (2h, PR/SR aligned, SINGLE_BOUNCE_NI, CH off). Wavefront 7 may be still valid for the "locked" measurement, to be checked by TCS experts.
At this point the acquisition should be going on, and the other 4 h of measurement left started (from the unlock onwards).
It is better to wait until approximately 5 LT before attempting to relock.
Bottom line: the situation about the peculiar way PyHWS is started should be made more robust, and/or hwsAna.py should be made more Python3-compliant.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}