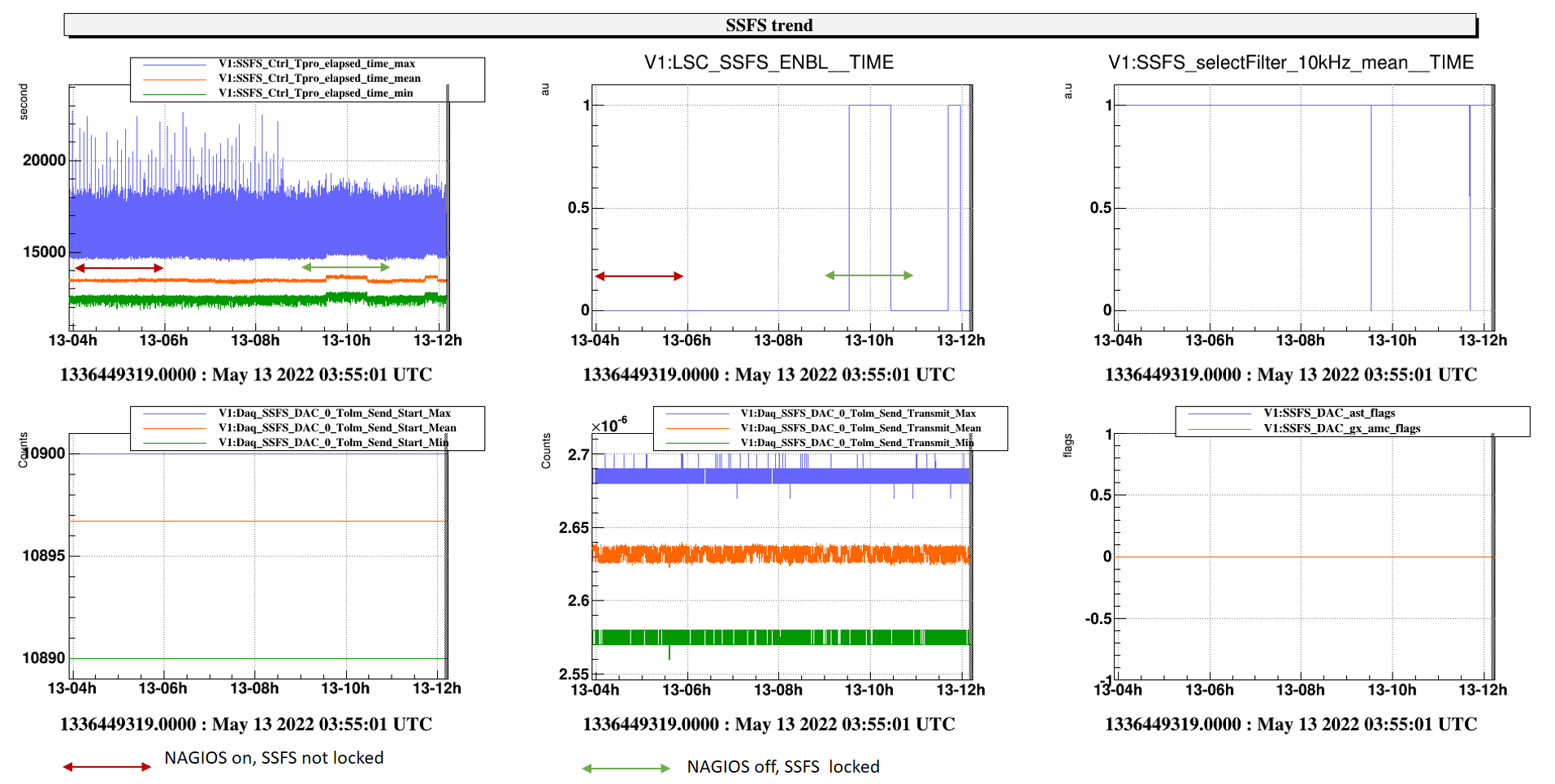
The ALS_CEB servers preiously running with the SSFS on the rtpc21(SSFS_rtpc) are now on the rtpc10(CEB_ALS_rtpc) :
- a new Tolm fpath has been setup to connect the rtpc10 link1 in the Computing room on the MxDx_v2_SN19 link13, thank to Francesco
- The CEB_ALS DBox SN86 is now managed by the CEB_ALS_dbox server . As consequence all the data provided by its mezzanines are sent now to the CEB_ALS_rtpc
The servers have been renamed CEB_ALS and CEB_ALS_BPC and the ARMS_LOCK metatron server python configuration has been upgraded accordingly .
After these updates, the ITF has been reloched at the LOCKED_ARMS_IR_ALS to adjust the ALS_CEB BPC PZT positions and then upto ACQUIRE_DRMI.
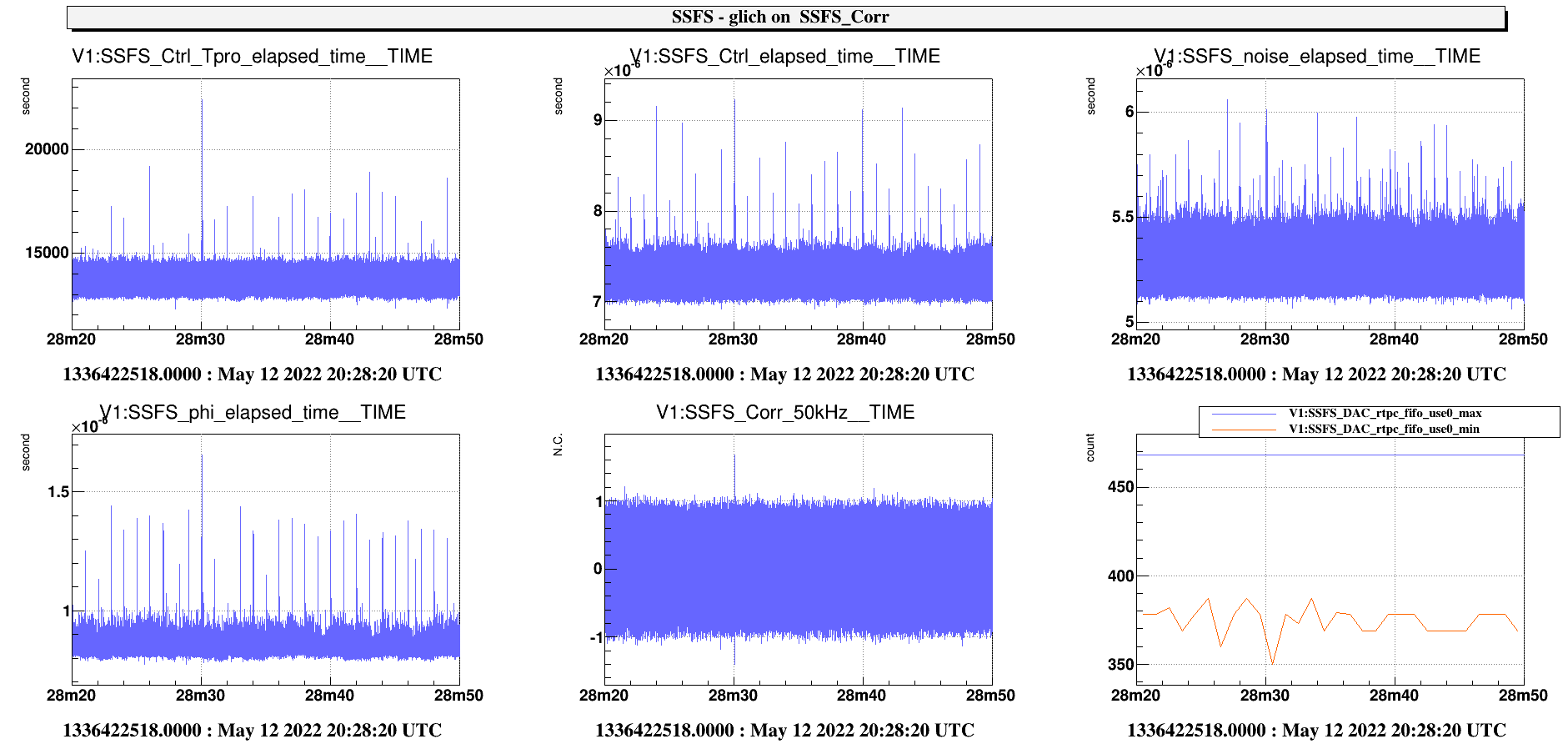
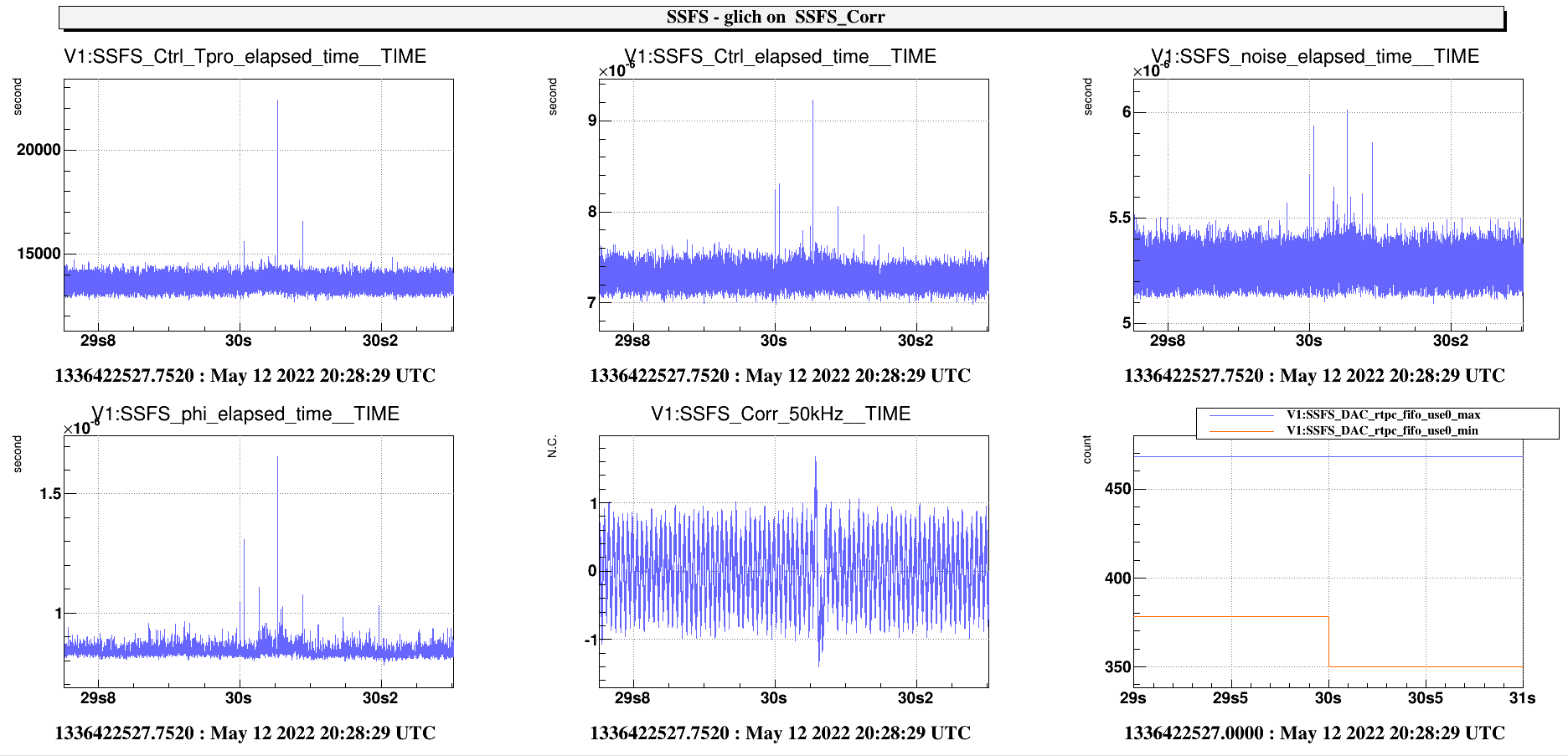
The attached plots compare the SSFS servers elapsed_time , with the ALS_CEB tasks(purple) and without(blue) : the overall cycle has been reduced by 1.4us







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}