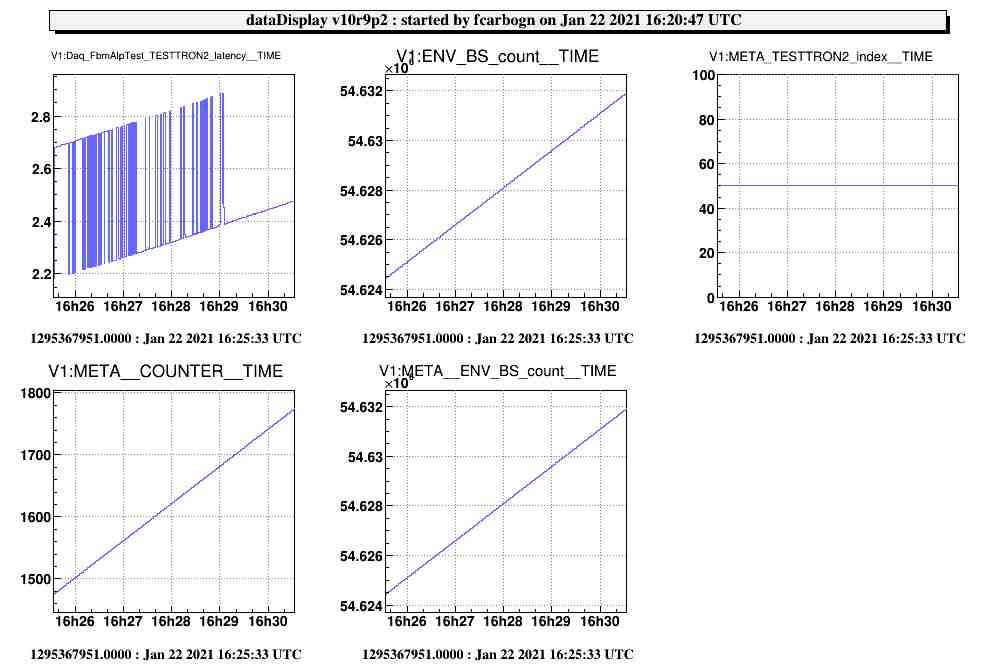
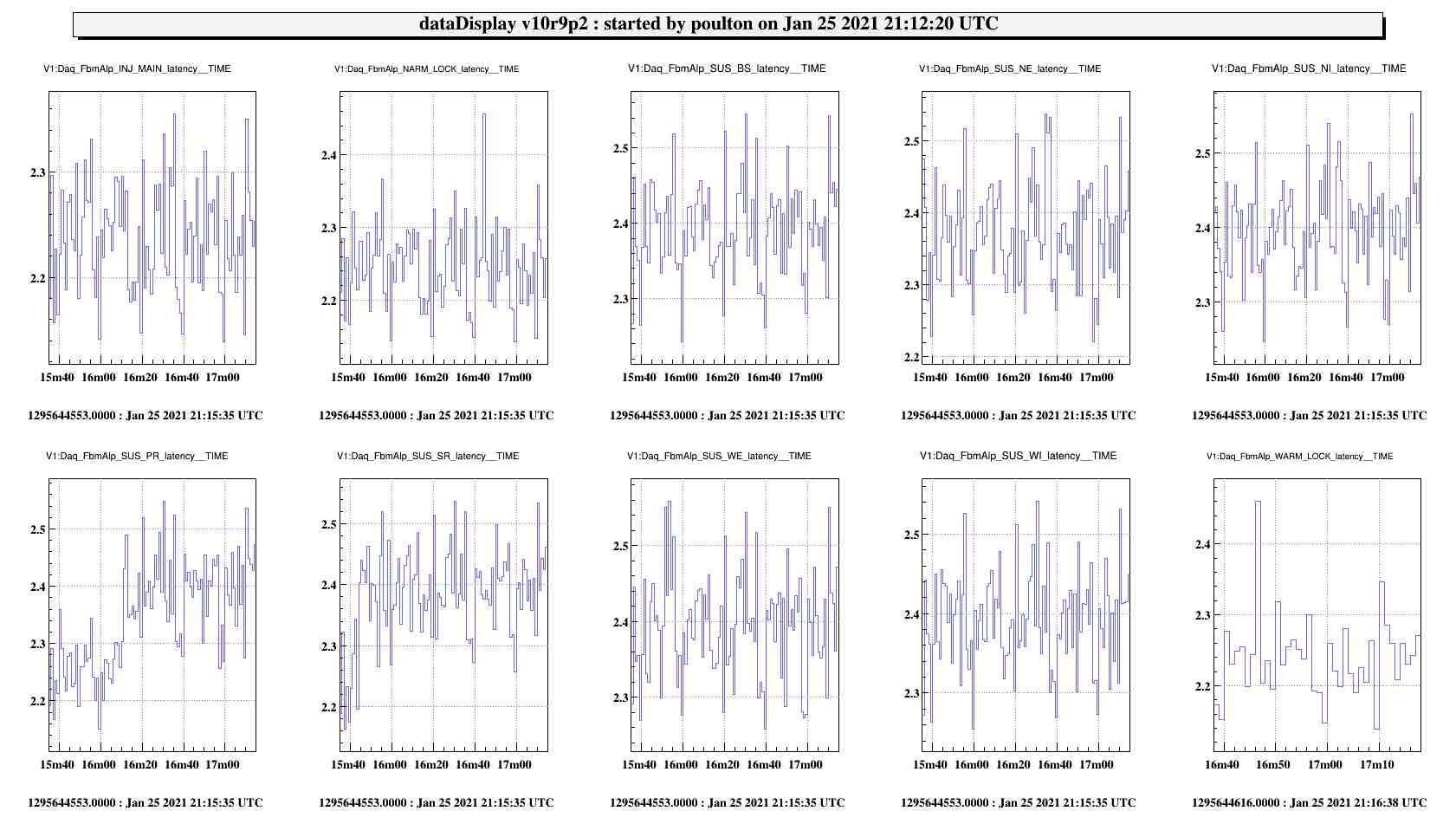
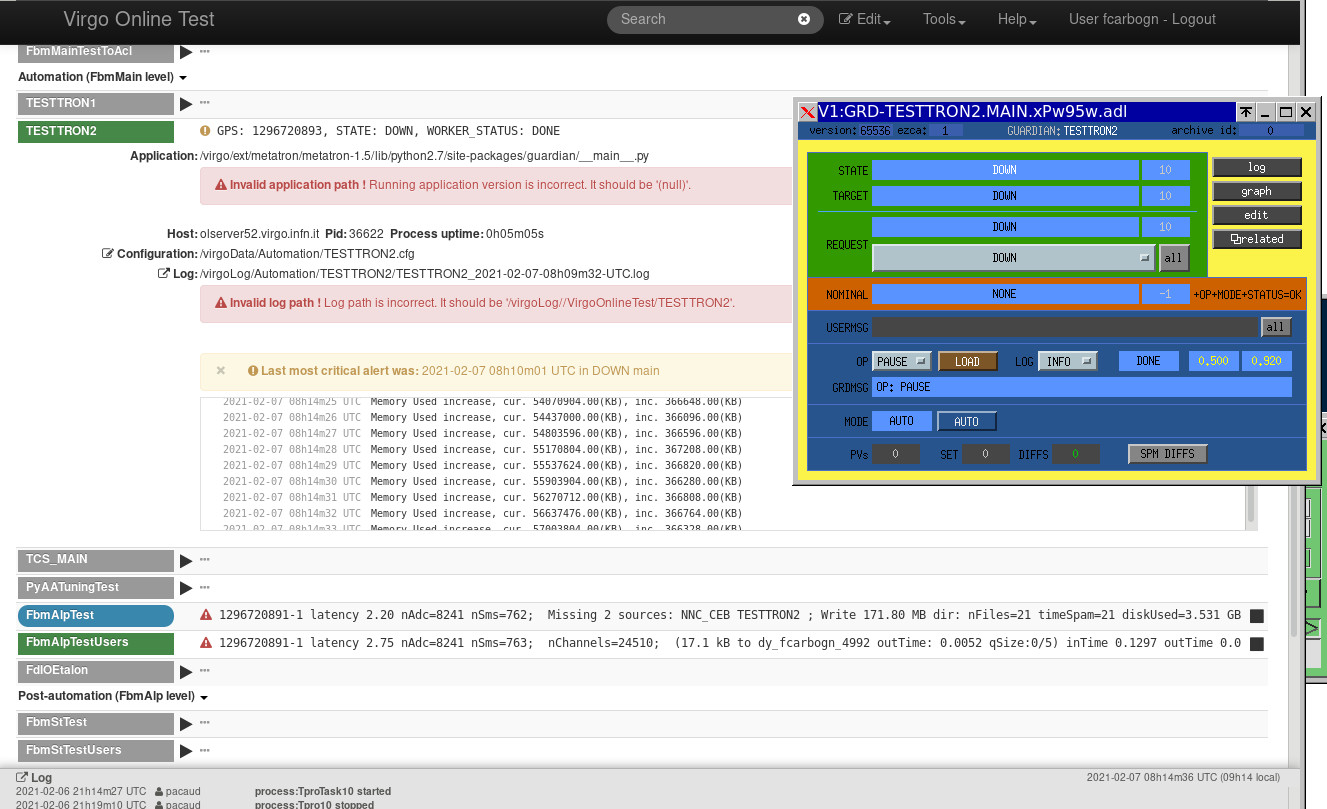
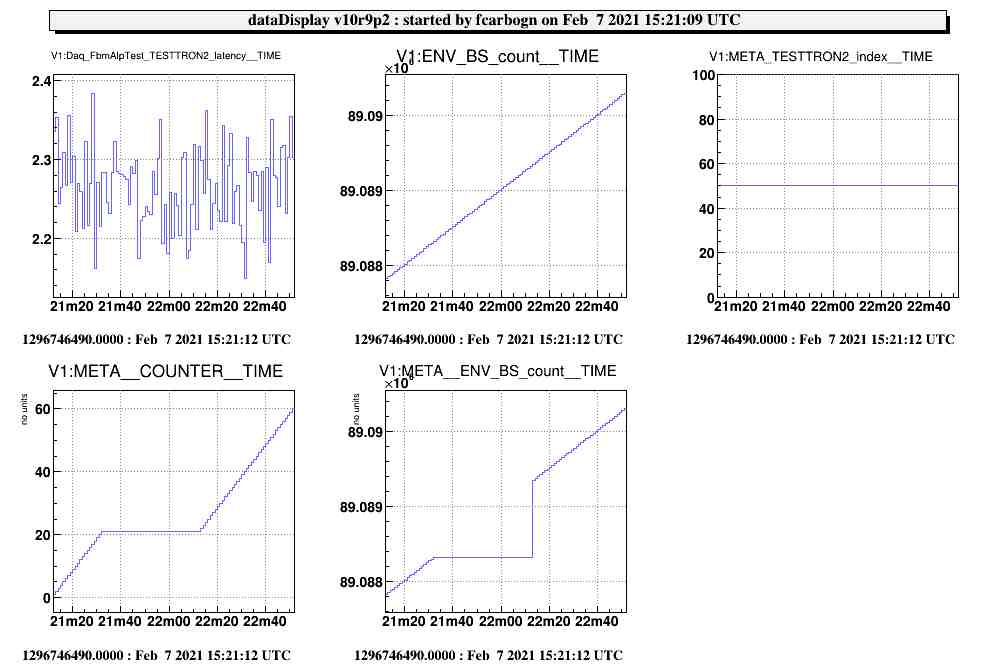
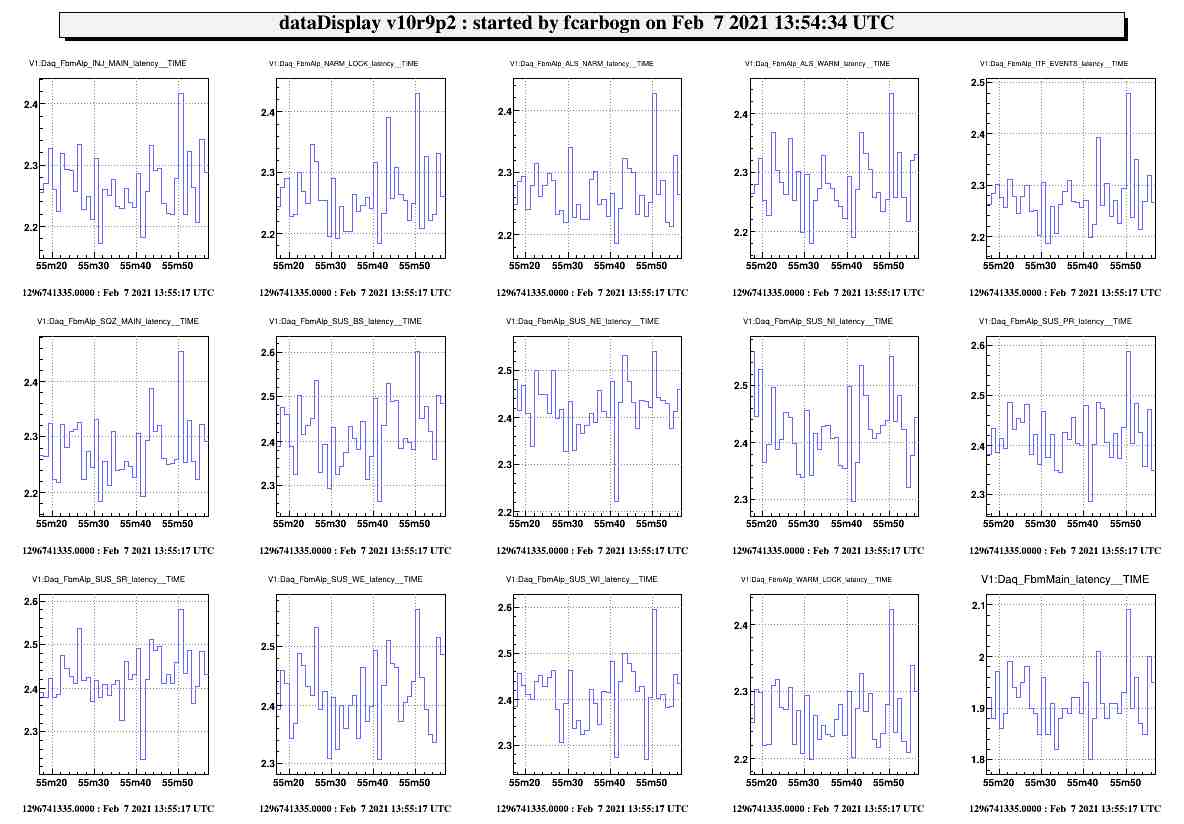
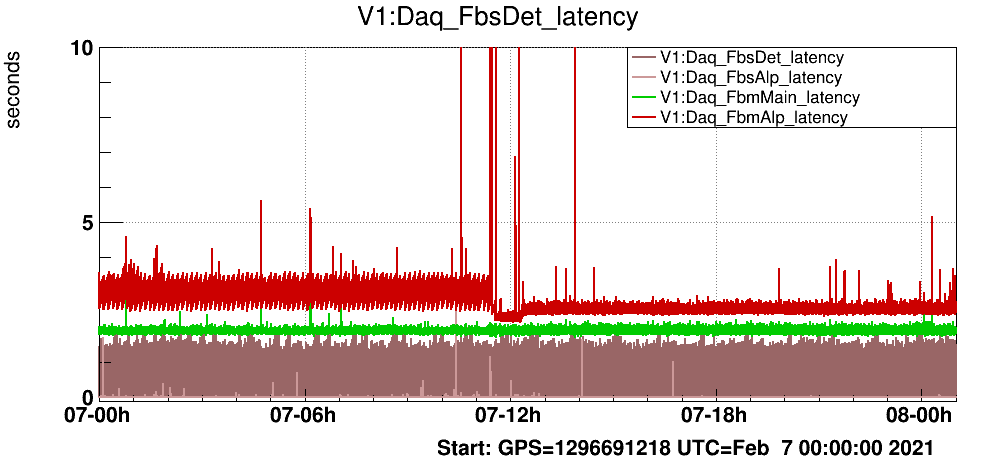
It has been known for some time (back already in O3) that the Automation nodes were characterized by a strange oscillating, increasing and then resetting back latency impacting the downstream DAQ (See Daq_FbmAlpTest_TESTTRON2_latency channel on Fig. 1 and 2).
This behaviour has been investigated and traced back to the way the metatron nodes are plugged in into the DAQ chain within the ezca library.
Modifications have been made on the main metatron/DAQ integration loop making it more similar to the one implemented into the PyALP application and boling down into respecting the following order while dealing with frames in the loop:
- frame.close()
- frame = fdio.get_frame()
- out_frame = frame.copy()
- out_frame.write_sms_prefix(.....)
- fdio.put_frame(out_frame)
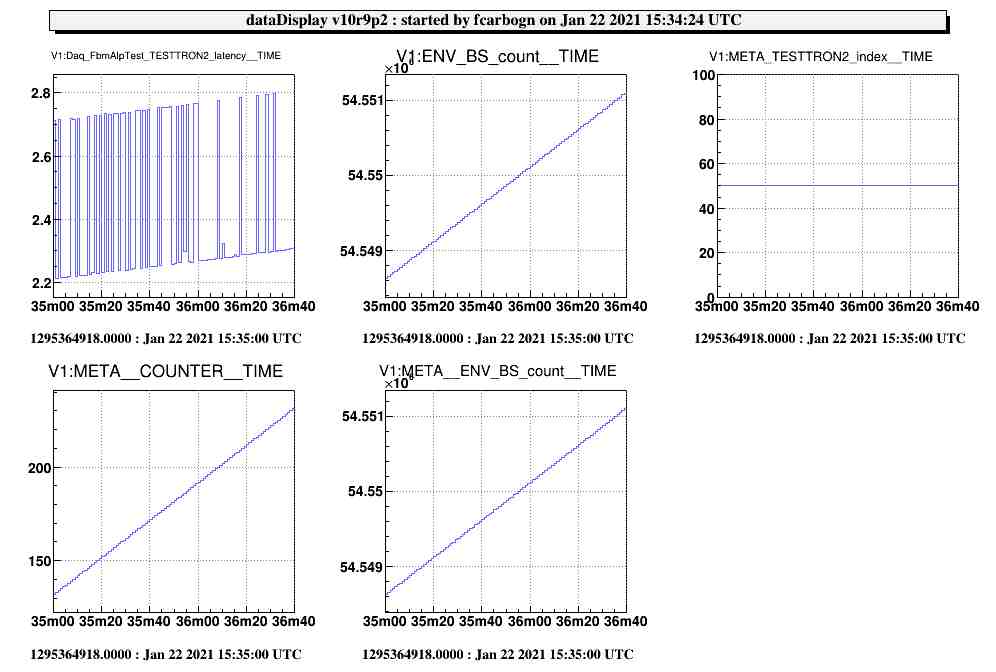
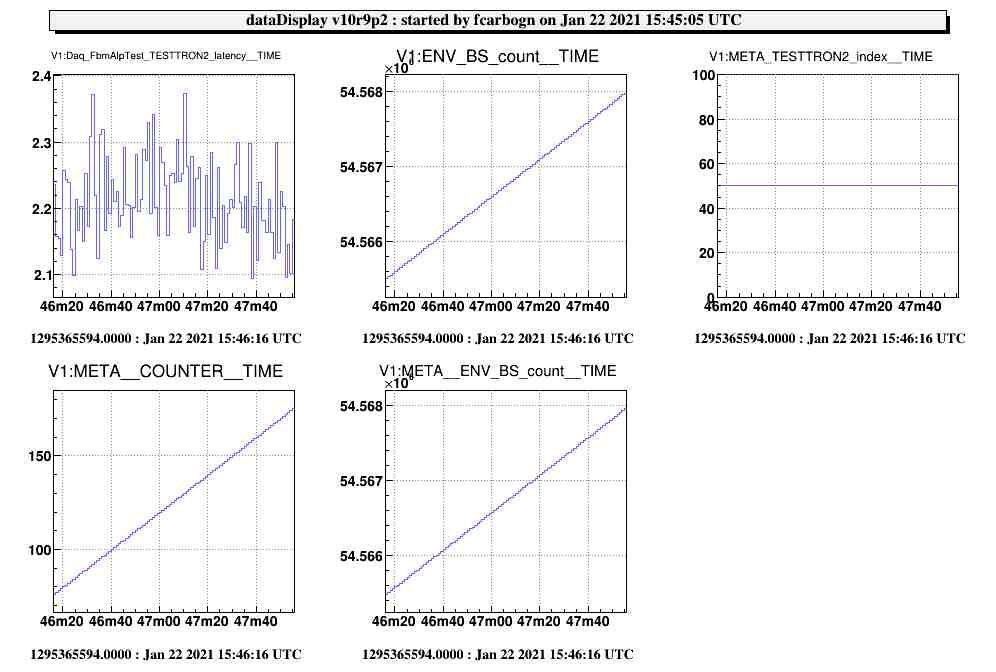
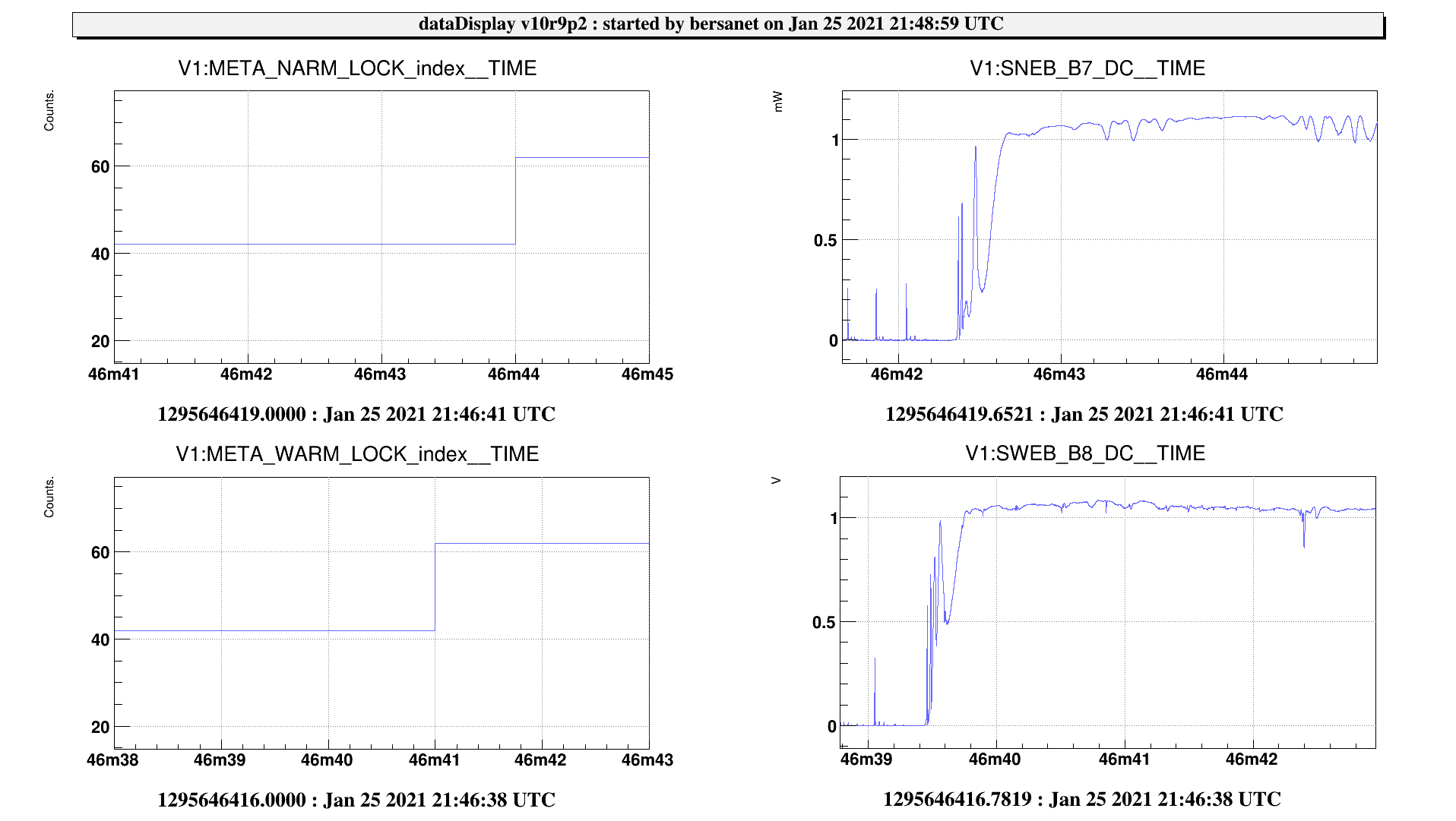
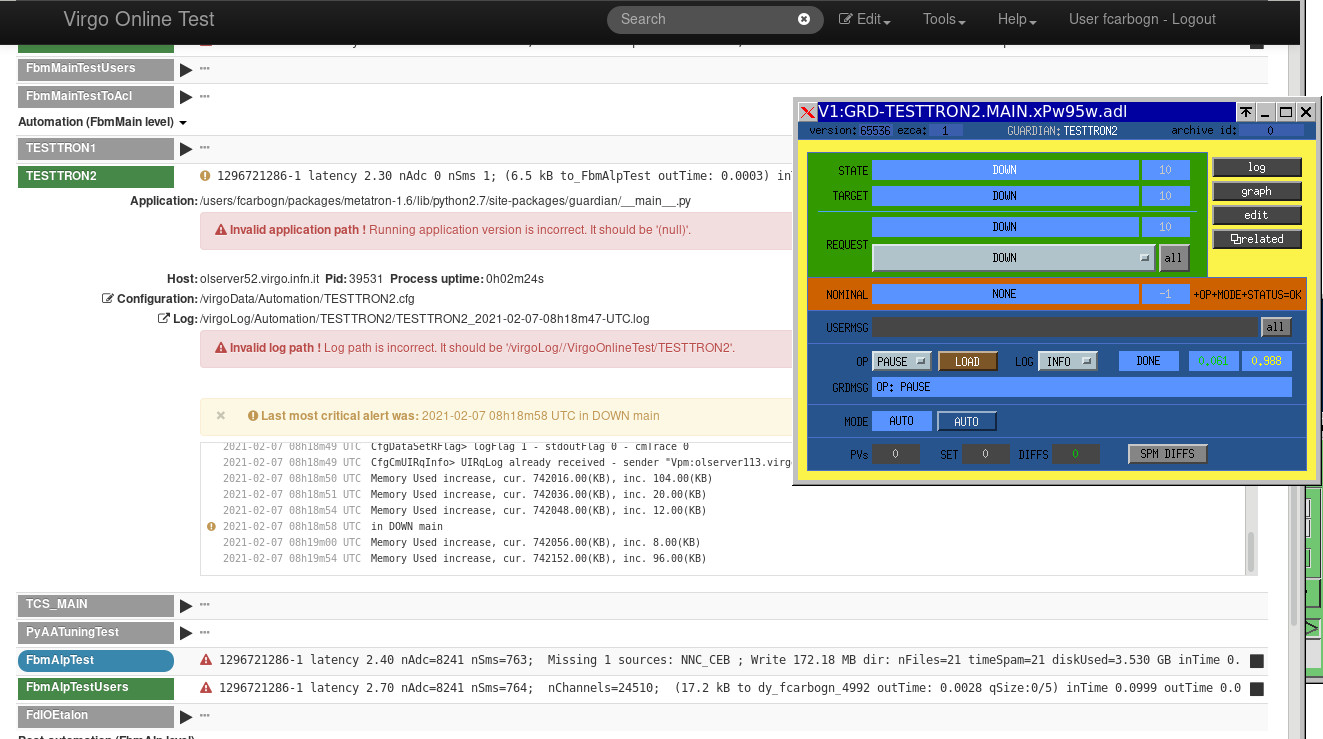
Those modification have been implemented into metatron-1.5 and tested within the VirgoOnlineTest framework. Results can be seen on Fig. 3 were the latency of the TESTTRON2 node is now fluctuating around an average value (approx 2.2sec). The behaviour of the channels accessed into the user code seems unaffected (as shown by the count/COUNTER channels).
We intend to put in operation this new version of metatron on the dedicated shift next Monday afternoon










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}